Two years ago, I still planned to implement a new version of AsyncGetCallTrace in Java. This plan didn’t materialize, but Erik Österlund had the idea to fully walk the stack at safepoints during the discussions. Walking stacks only at safepoints normally would incur a safepoint-bias (see The Inner Workings of Safepoints), but when you record some program state in signal handlers, you can prevent this. I wrote about this idea and its basic implementation in Taming the Bias: Unbiased Safepoint-Based Stack Walking. I’ll revisit this topic in this week’s short blog post because Markus Grönlund took Erik’s idea and started implementing it for the standard JFR method sampler:
Smartphones are more powerful then ever, with processors rivaling old laptops. So let’s try to use them like a laptop to develop web-applications on the go. In this weeks blog post I’ll show you how to do use run and develop a CAP JavaSpring Boot application on your smartphone and how to run VSCode locally to develop and modify it. This, of course, works only on Android phones, as they are a Linux at their core.
Welcome back to my hello-ebpf series. Last week, I was an attendee at a scheduling and power management summit (and to bring someone a sched-ext-themed birthday cake), and the Chemnitz Linux Days, so this blog post will be a bit shorter but cover a small scheduler that I wrote for Chemnitz.
In all of my eBPF presentations, I quote Brendan Gregg with his statement, “eBPF is a crazy technology, it’s like putting JavaScript into the Linux kernel.” and a picture of him shouting at hard drives. I took this picture from the following video where he demonstrates that his disk-read-latency measurement tool can detect if someone shouts at the hard drives:
Andrea Righi came up with the idea of writing a tiny scheduler that reacts to sound. The great thing about sched-ext and eBPF is that we can write experimental schedulers without much effort, especially if you use my hello-ebpf library and access the vast Java ecosystem.
For this scheduler, we scale the number of cores any task can use by the loudness level. So shouting at your computer makes your application run faster:
In this scenario, I ran the slow roads game while my system was exhausted by stress-ng, so more cores mean a less overcommitted system and, thereby, a more fluent gaming experience.
Around ten months ago I wrote a blog post together with Mikaël Francoeur on how to instrument instrumenters:
Have you ever wondered how libraries like Spring and Mockito modify your code at run-time to implement all their advanced features? Wouldn’t it be cool to get a peek behind the curtains? This is the premise of my meta-agent, a Java agent to instrument instrumenters, to get these insights and what this blog post is about.
This launched a website under localhost:7071 where you could view the actions of every instrument and transformer. The only problem? It’s cumbersome to use, especially programmatically. Join me in this short blog post to learn about the newest edition of meta-agent and what it can offer.
Instrumentation Handler
An idea that came up at the recent ConFoo conference in discussion with Mikaël and Jonatan Ivanov was to add a new handler mechanism to call code every time a new transformer is added or a class is instrumented. So I got to work.
Welcome back to my hello-ebpf series. I was a FOSDEM earlier this month and gave three(ish) talks. This blog post covers one of them, which is related to concurrency testing.
Backstory
The whole story started in the summer of last year when I thought about the potential use cases for custom Linux schedulers. The only two prominent use cases at the time were:
Improve performance on servers and heterogenous systems
Allow people to write their own schedulers for educational purposes
Of course, the latter is also important for the hello-ebpf project, which allows Java developers to create their own schedulers. But I had another idea back then: Why can’t we use custom Linux schedulers for concurrency testing? I presented this idea in my keynote at the eBPF summit in September, which you can watch here.
I ended up giving this talk because of a certain Bill Mulligan, who liked the idea of showing my eBPF SDK in Java and sched-ext in a single talk. For whatever reason, I foolishly agreed to give the talk and spent a whole weekend in Oslo before JavaZone frantically implementing sched-ext support in hello-ebpf.
My idea then was one could use a custom scheduler to test specific scheduling orders to find (and possibly) reproduce erroneous behavior of concurrent code. One of the examples in my talk was dead-locks:
If you’re here for eBPF content, this blog post is not for you. I recommend reading an article on a concurrency fuzzing scheduler at LWN.
Ever wonder how the JDK Flight Recorder (JFR) keeps track of the classes and methods it has collected for stack traces and more? In this short blog post, I’ll explore JFR tagging and how it works in the OpenJDK.
Tags
JFR files consist of self-contained chunks. Every chunk contains:
The maximum chunk size is usually 12MB, but you can configure it:
java -XX:FlightRecorderOptions:maxchunksize=1M
Whenever JFR collects methods or classes, it has to somehow tell the JFR writer which entities have been used so that their mapping can be written out. Each entity also has to have a tracing ID that can be used in the events that reference it.
This is where JFR tags come in. Every class, module, and package entity has a 64-bit value called _trace_id (e.g., classes). Which consists of both the ID and the tag. Every method has an _orig_method_idnum, essentially its ID and a trace flag, which is essentially the tag.
In a world without any concurrency, the tag could just be a single bit, telling us whether an entity is used. But in reality, an entity can be used in the new chunk while we’re writing out the old chunk. So, we need to have two distinctive periods (0 and 1) and toggle between them whenever we write a chunk.
Tagging
We can visualize the whole life cycle of a tag for a given entity:
In this example, the entity, a class, is brought into JFR by the method sampler (link) while walking another thread’s stack. This causes the class to be tagged and enqueued in the internal entity queue (and is therefore known to the JFR writer) if it hasn’t been tagged before (source):
This shows that tagging also prevents entities from being duplicated in a chunk.
Then, when a chunk is written out. First, a safepoint is requested to initialize the next period (the next chunk) and the period to be toggled so that the subsequent use of an entity now belongs to the new period and chunk. Then, the entity is written out, and its tag for the previous period is reset (code). This allows the aforementioned concurrency.
But how does it ensure that the tagged classes aren’t unloaded before they are emitted? By writing out the classes when any class is unloaded. This is simple yet effective and doesn’t need any change in the GC.
Conclusion
Tagging is used in JFR to record classes properly, methods, and other entities while also preventing them from accidentally being garbage collected before they are written out. This is a simple but memory-effective solution. It works well in the context of concurrency but assumes entities are used in the event creation directly when tagging them. It is not supported to tag the entities and then push them into the queue to later create events asynchronously. This would probably require something akin to reference counting.
Thanks for coming this far in a blog post on a profiling-related topic. I chose this topic because I wanted to know more about tagging and plan to do more of these short OpenJDK-specific posts.
Writing custom Linux schedulers is pretty easy using sched-ext. You can write your own tiny scheduler in a few lines of code using C, Rust, or even Java. We’re so confident in sched-ext that we’re starting a Scheduler Contest for FOSDEM’25. Think you can craft the ultimate scheduler? A scheduler that does something interesting, helpful, or fun? Join our sched-ext contest and show us what you’ve got, with the chance of winning hand-crafted sched-ext swag!
How to participate: Submit your scheduler using sched-ext as a pull request to the repository fosdem25, ensuring:
It runs with a 6.12 Linux kernel.
It’s GPLv2-licensed
It compiles and is understandable. We’re programming language agnostic; just make sure to include a script so we can build and run it.
The implementations.md document provides details on the submission format.
You can also submit a unique scheduling policy idea to ideas.md.
Try to surprise us…
Deadlines & Announcement:
The submission deadline is Sunday, 2 February, at 10:00 AM (CET).
To claim your prize, you must be present during Andrea’s talk. By participating, you agree to share your submission under GPL licensing and allow us to showcase it.
Legal Note: This contest is for fun! We, Andrea and Johannes, select the winners based on our personal preferences and our own definition of “best”. All decisions are final, and we’re not liable beyond delivering the prizes to the winners. If you have any questions, feel free to create a GitHub issue.
There will be multiple talks at FOSDEM’25 on sched-ext:
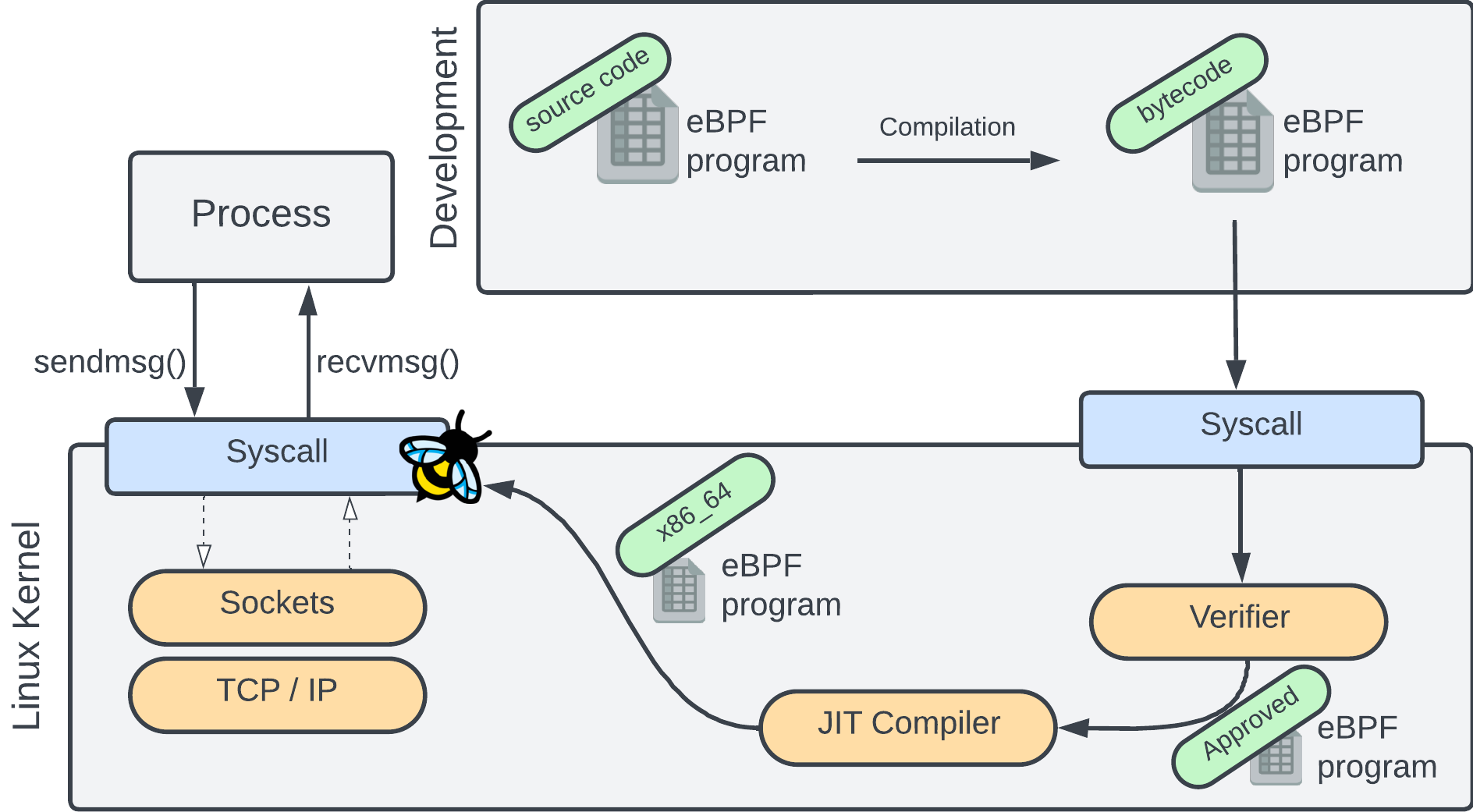
The eBPF verifier is a vital part of the eBPF stack. The verifier checks all eBPF bytecode that is loaded into the kernel:
Courtesy of Mohammed Aboullaite
This ensures that the bytecode is valid, that it doesn’t access potentially unsafe memory (like dereferencing null pointers), and that all programs terminate. This is vital for safe-guarding the kernel against common issues.
The only problem? The verifier output can be quite hard to understand. Consider for example the following verifier error log which only lists the bytecode:
It’s not entirely obvious what the error is and how to resolve it, especially for people new to eBPF.
This is why I’m starting eBPF Verifier Errors Project:
A project that aims to collect as many eBPF verifier logs as possible, with the related source code, a description of the issue, and how to resolve them. This creates a database where people can look up verifier errors and possibly use it as a data source for developer tooling (like AI chatbots).
The errors are collected in the form of issues in the ebpf-verifier-errors repository on GitHub. You can obtain a list on the command line via:
Please consider submitting your verifier errors today. It’s not hard; just fill out the issue form, and you’re done:
Any submission counts. We use GitHub issues because it makes submitting as easy as possible. No need to clone the repository and submit a pull request. Feel free to submit C, Rust, and Java code. If you find a submission that can improved, just add a comment.
If you’re unsure what a submission should look like, there are already five submissions by Dylan Reimerink and me, and possibly many more when you read this:
Conclusion
Verifier errors can be cryptic and frustrating, but we can change that. Let’s make them less scary and enrich the eBPF ecosystem. I’m happy that Dylan of ebpf-docs fame has agreed to join this worthy cause.
I pledge to contribute all eBPF verifier errors that I encounter and I look forward to your contributions.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.
To loop over all elements in the scheduling queue, to pick a random one, we had to write inline C code. A simplified version without scheduling priorities looks like the following:
@Override
public void dispatch(int cpu, Ptr<TaskDefinitions.task_struct> prev) {
String CODE = """
// pick a random task struct index
s32 random = bpf_get_prandom_u32() %
scx_bpf_dsq_nr_queued(SHARED_DSQ_ID);
struct task_struct *p = NULL;
bpf_for_each(scx_dsq, p, SHARED_DSQ_ID, 0) {
// iterate till we get to this number
random = random - 1;
// and try to dispatch it
if (random <= 0 &&
tryDispatching(BPF_FOR_EACH_ITER, p, cpu)) {
return 0;
}
};
return 0;
""";
}
This surely works, but inline C code is not the most readable and writing it is error-prone. I’ve written on this topic in my post Hello eBPF: Write your eBPF application in Pure Java (12) before. So what was keeping us from supporting the bpf_for_each macro? Support for lambdas as arguments to built-in bpf functions.
Lottery Scheduler in Pure Java
May I introduce you know the support for directly passed lambda expressions: This let’s us define a bpf_for_each_dsq function and to write a simple lottery scheduler in pure Java:
Eleven years ago, I was a student in Professor Frank Bellosa‘s operating systems course, learning about different schedulers. I wrote a blog post on a scheduler that I found particularly interesting: the lottery scheduler. I could write a new introduction to lottery scheduling, but I can also delegate this task to my old self:
I currently have a course covering operating systems at university. We learn in this course several scheduling algorithms. An operating system needs these kind of algorithms to determine which process to run at which time to allow these process to be executed “simultaniously” (from the users view).
Good scheduling algorithms have normally some very nice features:
They avoid the starving of one process (that one process can’t run at all and therefore makes no progress).
That all processes run the approriate percentage (defined by it’s priority) of time in each bigger time interval.
But they are maybe not only useful for operating systems but also for people like me. Probably they could help me to improve the scheduling of my learning.
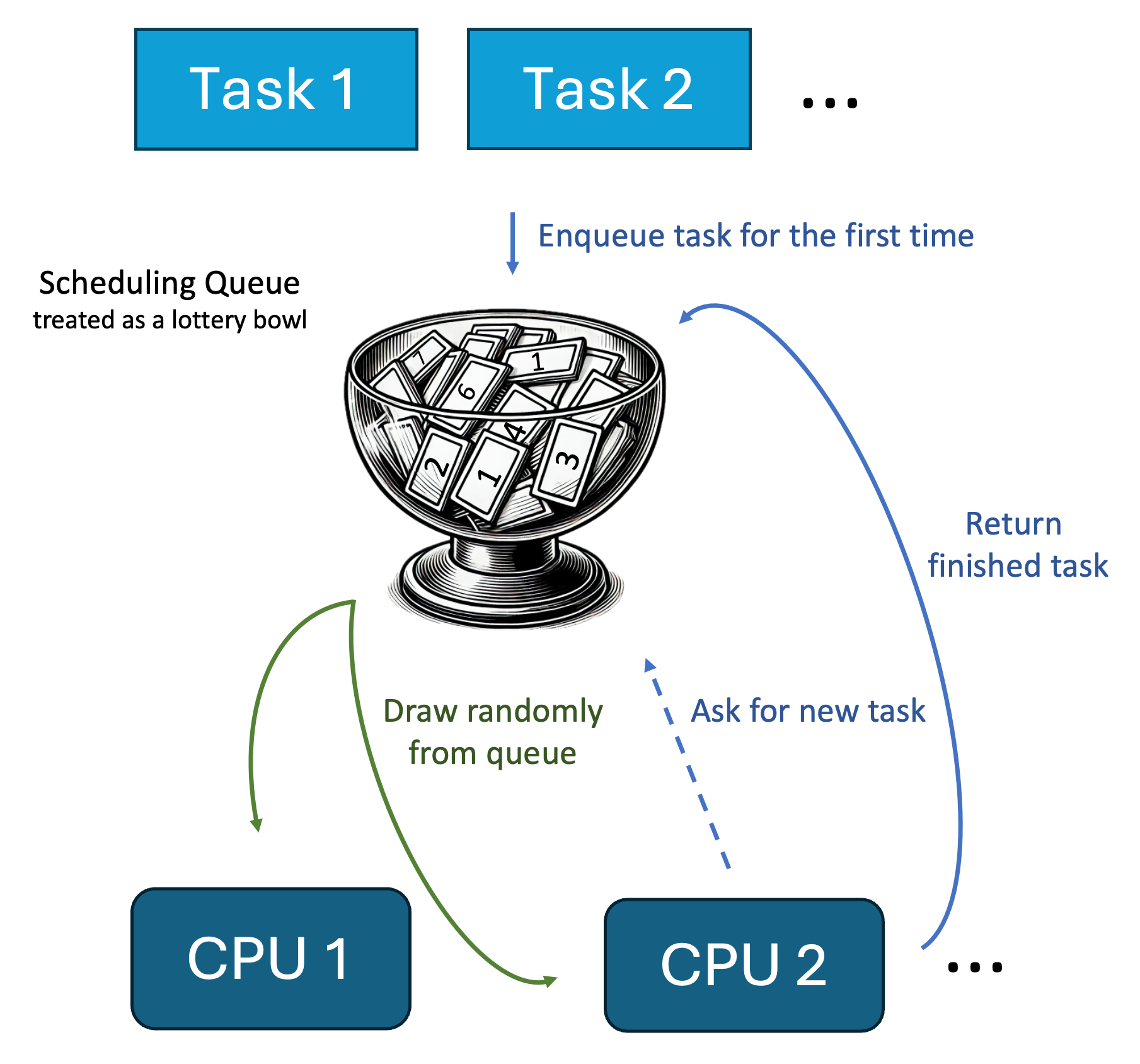
An algorithm that seems to be suited best for this purpose is called lottery scheduling (pdf). It’s an algorithm that gives a each process some lottery tickets (their number resembles the priority of the process). Every time the algorithm has to choose a new process to run, it simply picks a lottery ticket randomly and returns the process that owns the ticket. A useful addition is (in scenarios with only a few tickets) to remove the tickets that are picked temporarily from the lottery pot and put them back again, when the pot is empty.
We can visualize this similarly to the FIFO scheduler from last week’s blog post:
This is a truly random scheduler, making it great for testing applications with random scheduling orders. This is why it’s a great addition to the taskcontrol project.
Welcome back to my hello-ebpf series. A few weeks ago, I showed you how to write a minimal Linux scheduler in both Java and C using the new Linux scheduler extensions. Before we start: The Linux kernel with sched-ext support has finally been released, so the next Ubuntu version will probably have support for writing custom Linux schedulers out-of-the-box.
In this week’s blog posts, I’ll show you how to use a custom scheduler to control the execution of tasks and processes. The main idea is that I want to be able to tell a task (a single thread of a process) or a task group (usually a process) to stop for a few seconds. This can be helpful for testing the behaviour of programs in scheduling edge cases, when for example a consumer thread isn’t scheduled as it used to be normally.
Of course, we can achieve this without a custom Linux scheduler: We can just send the task a POSIX SIGSTOP signal and a SIGCONT signal when we want to continue it. But where is the fun in that? Also, some applications (I look at you, OpenJDK) don’t like it when you send signals to them, and they will behave strangely, as they can observe the signals.
Idea
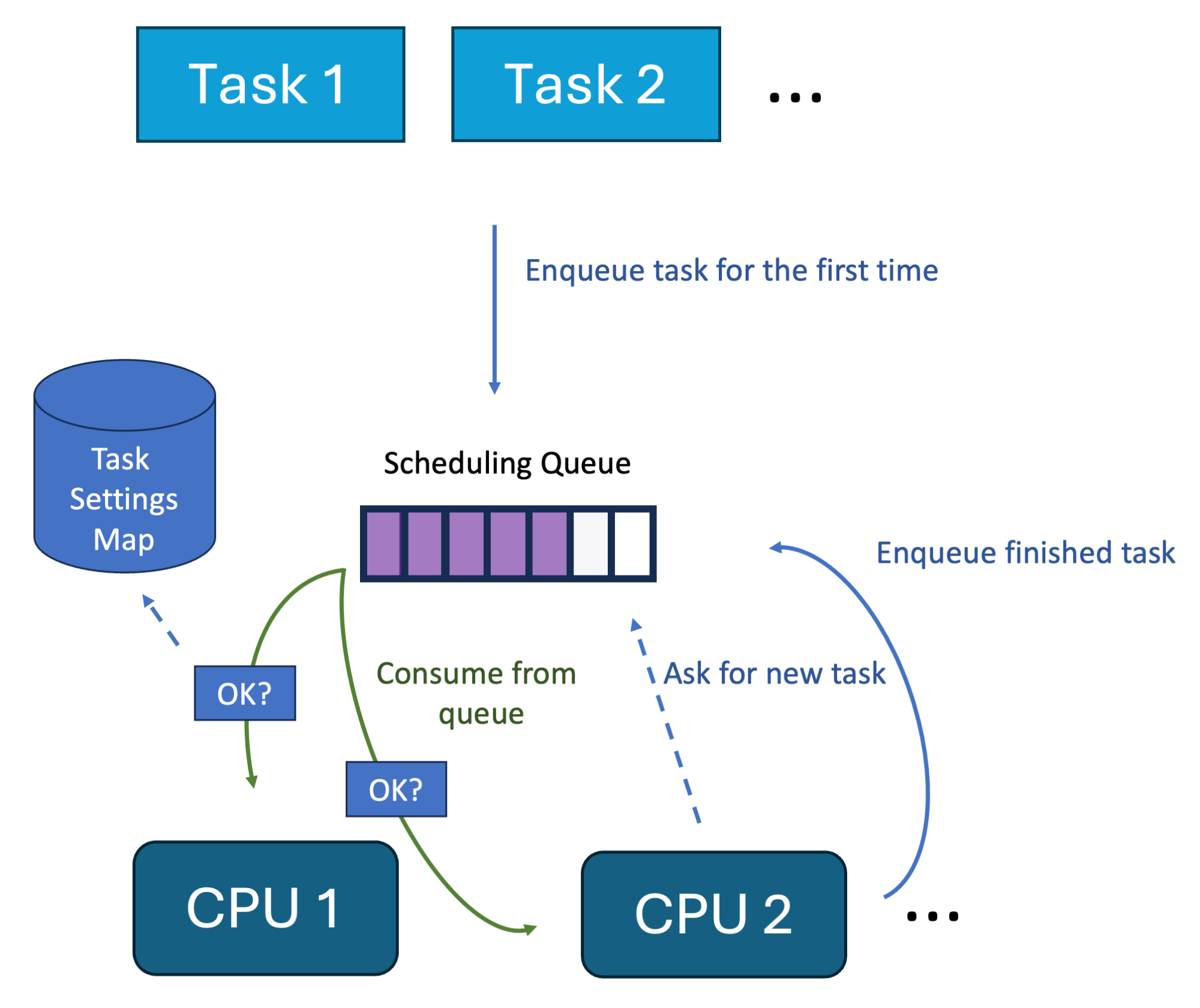
I showed before that we can write schedulers ourselves, so why not use them for this case? The main idea is to only schedule processes in the scheduler that are allowed to be scheduled, according to a task (and task group) settings BPF map:
This is essentially our minimal scheduler, with one slight modification that I show you later.
And yes, the tasks are not stopped immediately, but with a maximum of 5ms scheduling intervals, we only have a small delay.
I implemented all this in the taskcontrol project, which you can find on GitHub. This is where you also find information on the required dependencies and how to install a 6.12 Kernel if you’re on Ubuntu 24.10.
The following is a tutorial written for the sched_ext project, that gives you an introduction into writing a Linux scheduler directly in C. The tutorial is also present on the sched_ext scx wiki.
In the following a short tutorial for creating a minimal scheduler written with sched_ext in C. This scheduler uses a global scheduling queue from which every CPU gets its tasks to run for a time slice. The scheduler order is First-In-First-Out. So it essentially implements a round-robin scheduler:
This short tutorial covers the basics; to learn more, visit the resources from the scx wiki.
Almost to the day, a year ago, I published my blog post called Level-up your Java Debugging Skills with on-demand Debugging. In this blog post, I wrote about multiple rarely known and rarely used features of the Java debugging agent, including the onjcmd feature. To quote my own blog post:
JCmd triggered debugging
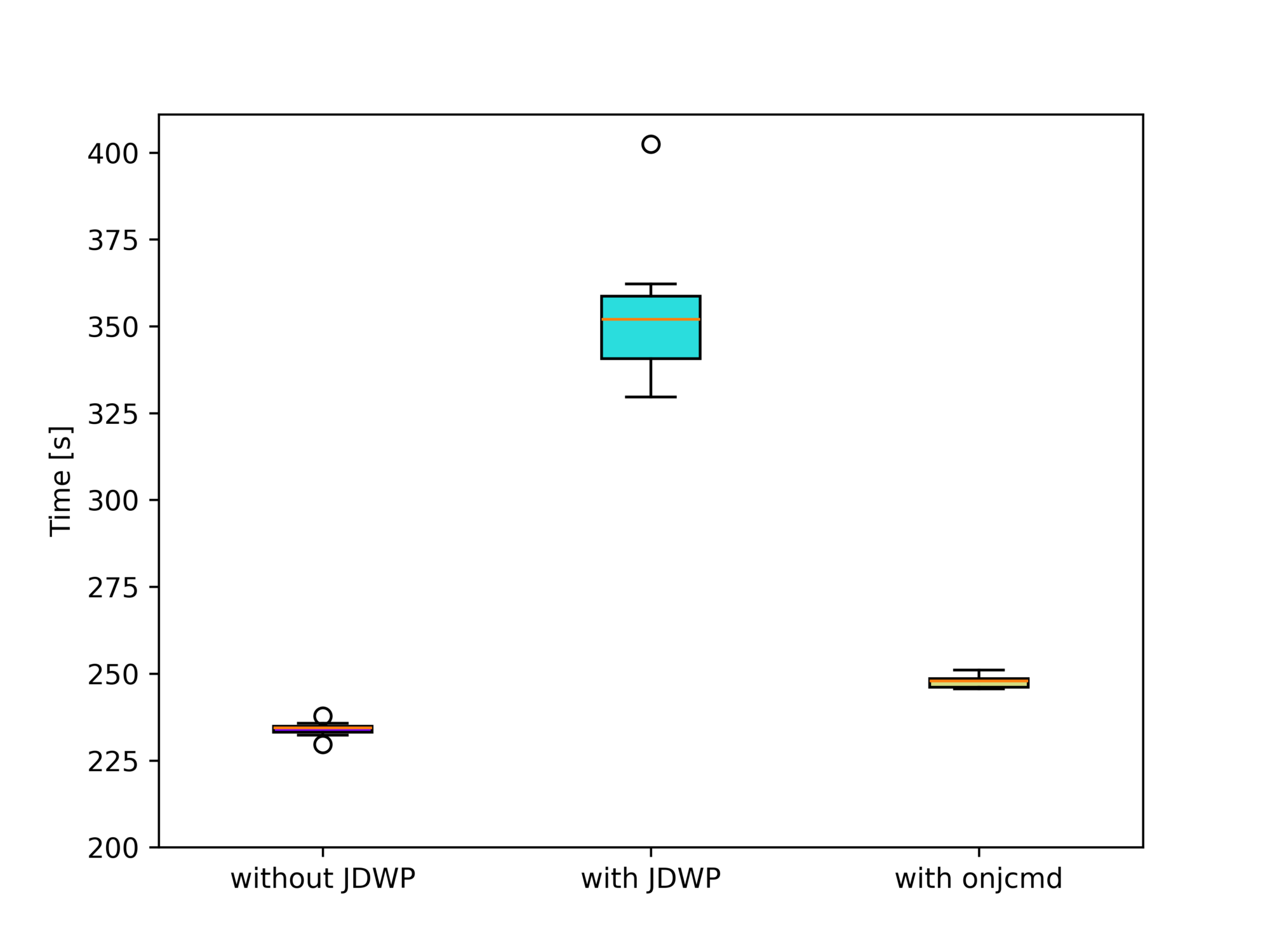
There are often cases where the code that you want to debug is executed later in your program’s run or after a specific issue appears. So don’t waste time running the debugging session from the start of your program, but use the onjcmd=y option to tell the JDWP agent to wait with the debugging session till it is triggered via jcmd.
The alternative to using this feature is to start the debugging session at the beginning and only connect to the JDWP agent when you want to start debugging. But this was, for a time, significantly slower than using the onjcmd feature (source):
This week, a short blog post on a question that bothered me this week: How can I get the operating systems thread ID for a given Java thread? This is useful when you want to deal with Java threads using native code (foreshadowing another blog post). The question was asked countless times on the internet, but I couldn’t find a comprehensive collection, so here’s my take. But first some background:
Background
In Java, normal threads are mapped 1:1 to operating system threads. This is not the case for virtual threads because they are multiplexed on fewer carrier threads than virtual threads, but we ignore these threads for simplicity here.
But what is an operating system thread? An operating system thread is an operating system task that shares the address space (and more) with other thread tasks of the same process/thread group. The main thread is the thread group leader; its operating system ID is the same as the process ID.
Be aware that the Java thread ID is not related to the operating system ID but rather to the Java thread creation order. Now, what different options do we have to translate between the two?
Different Options
During my research, I found three different mechanisms:
Using the gettid() method
Using JFR
Parsing thread dumps
In the end, I found that option 3 is best; you’ll see why in the following.
Or: Learn how to write a performant* Linux scheduler in 25 lines of Java code.
Welcome back to my series on ebpf. In the last post, I presented a recording of my JavaZone presentation on eBPF and a list of helpful resources for learning about the topic. Today, I’ll show you how to write a Linux scheduler in Java with eBPF. This blog post is the accompanying post to my eBPF summit keynote of the same title:
With my newest hello-ebpf addition, you can create a Linux scheduler by just implementing the methods of the Scheduler interface, allowing you to write a small scheduler with ease:
Is it really as easy as that? Of course not, at least not yet. Developing and running this scheduler requires a slightly modified version of hello-ebpf, which lives in the branch scx_demo, and a kernel patched with the sched-ext extension or a CachyOS instance with a 6.10 kernel, as well as some luck because it’s still slightly brittle.
Nonetheless, when you get it working, you can enter the wondrous world of people who build their schedulers with eBPF. You can find some of them on the sched-ext slack and many of their creation in the sched-ext/scx repository on GitHub. The kernel patches will hopefully be merged into the mainline kernel soon and will be available with version 6.12.
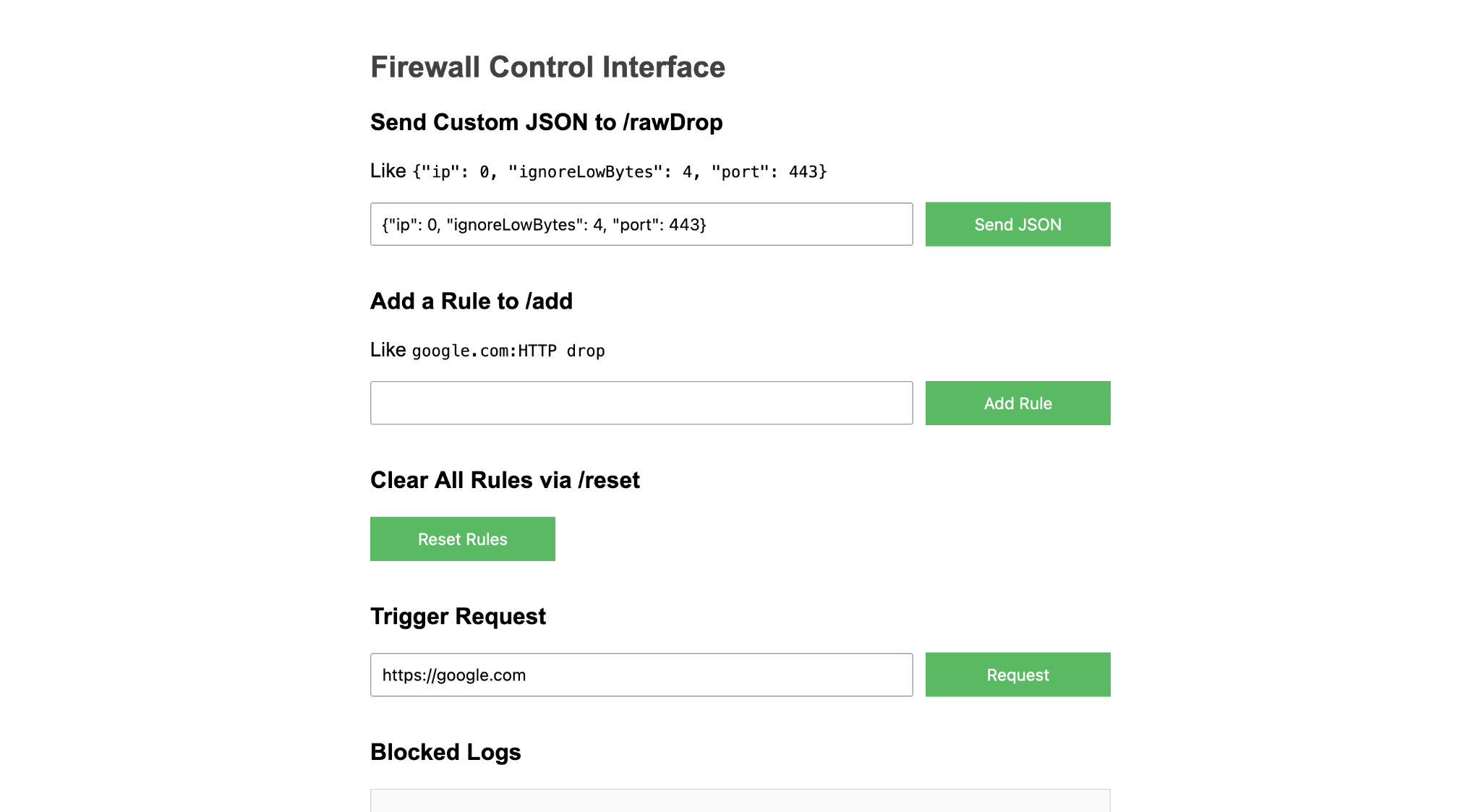
Welcome back to my series on ebpf. In the last post, I told you how to build a Firewall with Java and eBPF. I gave and will give the talk on the very same topic at multiple conferences, as mentioned at the end of the post. Last week, I gave it, together with Mohammed Aboullaite, at one of my favorite Java conferences: JavaZone. One of the reasons I recommend this conference to every upcoming speaker is that they create really good recordings of every talk and upload them to Vimeo almost immediately. So here is the recording of the talk:
Before I start, here is a disclaimer: The details of eBPF are hard, so I could only get the filtering of incoming packets to work reliably. Can I still call it a firewall? I would say yes, but please help me filter the outgoing packets if you disagree. Also, it’s my first Spring-Boot-based application, so please don’t judge it too harshly. Lastly, we only focus on IPv4 packets, so adding support for IPv6 rules is left to the reader.
Is it fast? Probably. I didn’t do any measurements myself, but research by Cloudflare suggests that XDP is far faster at dropping packets than the standard firewall.
Before we go into the details, first, the demo of the PacketLogger:
The logger captures the incoming and outgoing IP packets with their IP address, their protocol (TCP, UDP, OTHER), the TCP/UDP port, and the packet length. But before I show you how I implemented all this in Java, here is a short introduction to the Linux network stack:
Welcome back to my series on ebpf. In the last post, I told you about BTF and generating Java classes for all BPF types. This week, we’re using these classes to write a simple packet blocker in pure Java. This is the culmination of my efforts that started in my post Hello eBPF: Generating C Code (8), to reduce the amount of C code that you have to write to create your eBPF application.
This blog post took again longer than expected, but you’ll soon see why. And I dropped libbcc support along the way.
After my last blog post, you still had to write the eBPF methods in a String embedded in the Java application. So if you wanted to write a simple XDP-based packet blocker that blocks every third incoming packet, you wrote the actual XDP logic into a String-typed field named EBPF_PROGRAM. But we already can define the data types and global variables in Java, generating C code automatically. Can we do the same for the remaining C code? We can now. Introducing the new Java compiler plugin, that allows to you write the above in “pure” Java, using Java as a DSL for C (GitHub):
@BPF(license = "GPL") // define a license
public abstract class XDPDropEveryThirdPacket
extends BPFProgram implements XDPHook {
// declare the global variable
final GlobalVariable<@Unsigned Integer> count =
new GlobalVariable<>(0);
@BPFFunction
public boolean shouldDrop() {
return count.get() % 3 == 1;
}
@Override // defined in XDPHook, compiled to C
public xdp_action xdpHandlePacket(Ptr<xdp_md> ctx) {
// update count
count.set(count.get() + 1);
// drop based on count
return shouldDrop() ? xdp_action.XDP_DROP : xdp_action.XDP_PASS;
}
public static void main(String[] args)
throws InterruptedException {
try (XDPDropEveryThirdPacket program =
BPFProgram.load(XDPDropEveryThirdPacket.class)) {
program.xdpAttach(XDPUtil.getNetworkInterfaceIndex());
while (true) {
System.out.println("Packet count " +
program.count.get());
Thread.sleep(1000);
}
}
}
}
Welcome back to my series on ebpf. In the last post, we learned how to use global variables to communicate easily between user and kernel land. In this post, you’ll learn about the BPF Type Format (BTF) and how and why we generate Java code from it.
We start with the simple question of what is BTF:
VMLinux Header
In all BPF programs that we’ve written in this blog series, we included a specific header:
#include "vmlinux.h"
This header contains all of the fundamental types and definitions we need when writing our BPF programs. It contains simple definitions like the integer types used in many of the examples: